Analysis Workflow Example¶
TL;DR
- In addition to using RAPIDS to extract behavioral features, create plots, and clean sensor features, you can structure your data analysis within RAPIDS (i.e. creating ML/statistical models and evaluating your models)
- We include an analysis example in RAPIDS that covers raw data processing, feature extraction, cleaning, machine learning modeling, and evaluation
- Use this example as a guide to structure your own analysis within RAPIDS
- RAPIDS analysis workflows are compatible with your favorite data science tools and libraries
- RAPIDS analysis workflows are reproducible and we encourage you to publish them along with your research papers
Why should I integrate my analysis in RAPIDS?¶
Even though the bulk of RAPIDS current functionality is related to the computation of behavioral features, we recommend RAPIDS as a complementary tool to create a mobile data analysis workflow. This is because the cookiecutter data science file organization guidelines, the use of Snakemake, the provided behavioral features, and the reproducible R and Python development environments allow researchers to divide an analysis workflow into small parts that can be audited, shared in an online repository, reproduced in other computers, and understood by other people as they follow a familiar and consistent structure. We believe these advantages outweigh the time needed to learn how to create these workflows in RAPIDS.
We clarify that to create analysis workflows in RAPIDS, researchers can still use any data manipulation tools, editors, libraries or languages they are already familiar with. RAPIDS is meant to be the final destination of analysis code that was developed in interactive notebooks or stand-alone scripts. For example, a user can compute call and location features using RAPIDS, then, they can use Jupyter notebooks to explore feature cleaning approaches and once the cleaning code is final, it can be moved to RAPIDS as a new step in the pipeline. In turn, the output of this cleaning step can be used to explore machine learning models and once a model is finished, it can also be transferred to RAPIDS as a step of its own. The idea is that when it is time to publish a piece of research, a RAPIDS workflow can be shared in a public repository as is.
In the following sections we share an example of how we structured an analysis workflow in RAPIDS.
Analysis workflow structure¶
To accurately reflect the complexity of a real-world modeling scenario, we decided not to oversimplify this example. Importantly, every step in this example follows a basic structure: an input file and parameters are manipulated by an R or Python script that saves the results to an output file. Input files, parameters, output files and scripts are grouped into Snakemake rules that are described on smk files in the rules folder (we point the reader to the relevant rule(s) of each step).
Researchers can use these rules and scripts as a guide to create their own as it is expected every modeling project will have different requirements, data and goals but ultimately most follow a similar chainned pattern.
Hint
The example’s config file is example_profile/example_config.yaml and its Snakefile is in example_profile/Snakefile. The config file is already configured to process the sensor data as explained in Analysis workflow modules.
Description of the study modeled in our analysis workflow example¶
Our example is based on a hypothetical study that recruited 2 participants that underwent surgery and collected mobile data for at least one week before and one week after the procedure. Participants wore a Fitbit device and installed the AWARE client in their personal Android and iOS smartphones to collect mobile data 24/7. In addition, participants completed daily severity ratings of 12 common symptoms on a scale from 0 to 10 that we summed up into a daily symptom burden score.
The goal of this workflow is to find out if we can predict the daily symptom burden score of a participant. Thus, we framed this question as a binary classification problem with two classes, high and low symptom burden based on the scores above and below average of each participant. We also want to compare the performance of individual (personalized) models vs a population model.
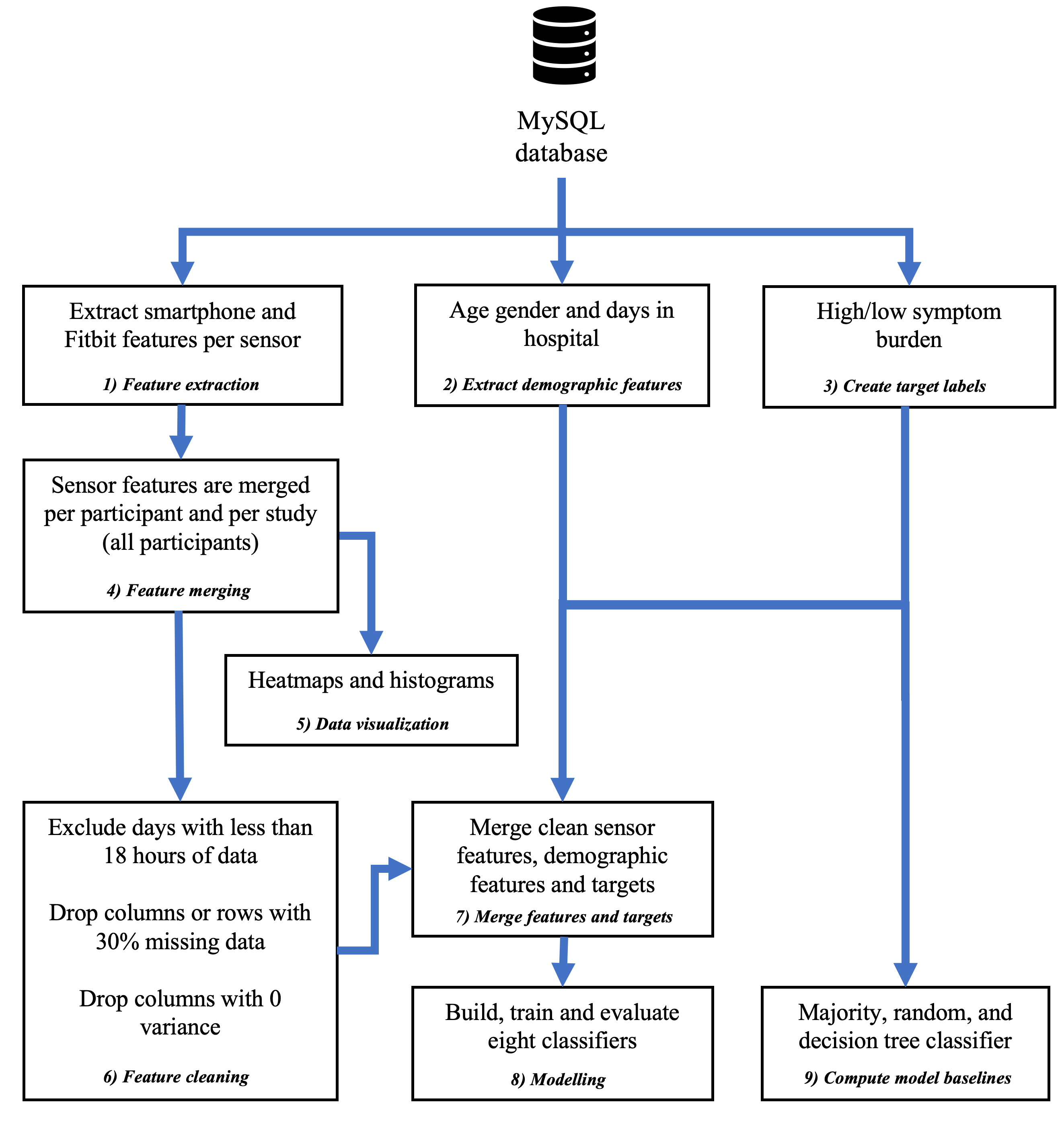
In total, our example workflow has nine steps that are in charge of sensor data preprocessing, feature extraction, feature cleaning, machine learning model training and model evaluation (see figure below). We ship this workflow with RAPIDS and share files with test data in an Open Science Framework repository.
Configure and run the analysis workflow example¶
- Install RAPIDS
- Unzip the CSV files inside rapids_example_csv.zip in
data/external/example_workflow/*.csv. - Create the participant files for this example by running:
./rapids -j1 create_example_participant_files - Run the example pipeline with:
./rapids -j1 --profile example_profile
Note you will see a lot of warning messages, you can ignore them since they happen because we ran ML algorithms with a small fake dataset.
Modules of our analysis workflow example¶
1. Feature extraction
We extract daily behavioral features for data yield, received and sent messages, missed, incoming and outgoing calls, resample fused location data using Doryab provider, activity recognition, battery, Bluetooth, screen, light, applications foreground, conversations, Wi-Fi connected, Wi-Fi visible, Fitbit heart rate summary and intraday data, Fitbit sleep summary data, and Fitbit step summary and intraday data without excluding sleep periods with an active bout threshold of 10 steps. In total, we obtained 245 daily sensor features over 12 days per participant.
2. Extract demographic data.
It is common to have demographic data in addition to mobile and target (ground truth) data. In this example we include participants’ age, gender and the number of days they spent in hospital after their surgery as features in our model. We extract these three columns from the data/external/example_workflow/participant_info.csv file. As these three features remain the same within participants, they are used only on the population model. Refer to the demographic_features rule in rules/models.smk.
3. Create target labels.
The two classes for our machine learning binary classification problem are high and low symptom burden. Target values are already stored in the data/external/example_workflow/participant_target.csv file. A new rule/script can be created if further manipulation is necessary. Refer to the parse_targets rule in rules/models.smk.
4. Feature merging.
These daily features are stored on a CSV file per sensor, a CSV file per participant, and a CSV file including all features from all participants (in every case each column represents a feature and each row represents a day). Refer to the merge_sensor_features_for_individual_participants and merge_sensor_features_for_all_participants rules in rules/features.smk.
5. Data visualization.
At this point the user can use the five plots RAPIDS provides (or implement new ones) to explore and understand the quality of the raw data and extracted features and decide what sensors, days, or participants to include and exclude. Refer to rules/reports.smk to find the rules that generate these plots.
6. Feature cleaning.
In this stage we perform four steps to clean our sensor feature file. First, we discard days with a data yield hour ratio less than or equal to 0.75, i.e. we include days with at least 18 hours of data. Second, we drop columns (features) with more than 30% of missing rows. Third, we drop columns with zero variance. Fourth, we drop rows (days) with more than 30% of missing columns (features). In this cleaning stage several parameters are created and exposed in example_profile/example_config.yaml.
After this step, we kept 173 features over 11 days for the individual model of p01, 101 features over 12 days for the individual model of p02 and 117 features over 22 days for the population model. Note that the difference in the number of features between p01 and p02 is mostly due to iOS restrictions that stops researchers from collecting the same number of sensors than in Android phones.
Feature cleaning for the individual models is done in the clean_sensor_features_for_individual_participants rule and for the population model in the clean_sensor_features_for_all_participants rule in rules/models.smk.
7. Merge features and targets.
In this step we merge the cleaned features and target labels for our individual models in the merge_features_and_targets_for_individual_model rule in rules/features.smk. Additionally, we merge the cleaned features, target labels, and demographic features of our two participants for the population model in the merge_features_and_targets_for_population_model rule in rules/features.smk. These two merged files are the input for our individual and population models.
8. Modelling.
This stage has three phases: model building, training and evaluation.
In the building phase we impute, normalize and oversample our dataset. Missing numeric values in each column are imputed with their mean and we impute missing categorical values with their mode. We normalize each numeric column with one of three strategies (min-max, z-score, and scikit-learn package’s robust scaler) and we one-hot encode each categorial feature as a numerical array. We oversample our imbalanced dataset using SMOTE (Synthetic Minority Over-sampling Technique) or a Random Over sampler from scikit-learn. All these parameters are exposed in example_profile/example_config.yaml.
In the training phase, we create eight models: logistic regression, k-nearest neighbors, support vector machine, decision tree, random forest, gradient boosting classifier, extreme gradient boosting classifier and a light gradient boosting machine. We cross-validate each model with an inner cycle to tune hyper-parameters based on the Macro F1 score and an outer cycle to predict the test set on a model with the best hyper-parameters. Both cross-validation cycles use a leave-one-out strategy. Parameters for each model like weights and learning rates are exposed in example_profile/example_config.yaml.
Finally, in the evaluation phase we compute the accuracy, Macro F1, kappa, area under the curve and per class precision, recall and F1 score of all folds of the outer cross-validation cycle.
Refer to the modelling_for_individual_participants rule for the individual modeling and to the modelling_for_all_participants rule for the population modeling, both in rules/models.smk.
9. Compute model baselines.
We create three baselines to evaluate our classification models.
First, a majority classifier that labels each test sample with the majority class of our training data. Second, a random weighted classifier that predicts each test observation sampling at random from a binomial distribution based on the ratio of our target labels. Third, a decision tree classifier based solely on the demographic features of each participant. As we do not have demographic features for individual model, this baseline is only available for population model.
Our baseline metrics (e.g. accuracy, precision, etc.) are saved into a CSV file, ready to be compared to our modeling results. Refer to the baselines_for_individual_model rule for the individual model baselines and to the baselines_for_population_model rule for population model baselines, both in rules/models.smk.