Overview¶
Let’s review some key concepts we use throughout these docs:
| Definition | Description |
|---|---|
| Device | A mobile or wearable device, like smartphones, Fitbit wrist bands, Oura Rings, etc. |
| Sensor | A physical or digital module builtin in a device that produces a data stream. For example, a smartphone’s accelerometer or screen. |
| Data Stream | Set of sensor data collected using a specific device with a particular ** format** and stored in a specific container. For example, smartphone (device) data collected with the AWARE Framework (format) and stored in a MySQL database (container). |
| Data Stream Format | Sensor data produced by a data stream have columns with specific names and types. RAPIDS can process a data stream using a format.yaml file that describes the raw data columns and any necessary transformations. |
| Data Stream Container | Sensor data produced by a data stream can be stored in a database, electronic files, or arbitrary electronic containers. RAPIDS can pull (download) the data from a stream using a container script implemented in R or Python. |
| Participant | A person that took part in a monitoring study |
| Behavioral feature | A metric computed from raw sensor data quantifying the behavior of a participant. For example, time spent at home calculated from location data. These are also known as digital biomarkers |
| Time segment | Time segments (or epochs) are the time windows on which RAPIDS extracts behavioral features. For example, you might want to compute participants’ time at home every morning or only during weekends. You define time segments in a CSV file that RAPIDS processes. |
| Time zone | A string like America/New_York that represents a time zone where a device logged data. You can process data collected in single or multiple time zones for every participant. |
| Feature Provider | A script that creates behavioral features for a specific sensor. Providers are created by the core RAPIDS team or by the community, which are named after its first author like [PHONE_LOCATIONS][DORYAB]. |
| config.yaml | A YAML file where you can modify parameters to process data streams and behavioral features. This is the heart of RAPIDS and the file that you will change the most. |
| credentials.yaml | A YAML file where you can define credential groups (user, password, host, etc.) if your data stream needs to connect to a database or Web API |
| Participant file(s) | A YAML file that links one or more smartphone or wearable devices used by a single participant. RAPIDS needs one file per participant. |
What can I do with RAPIDS?
- Extract behavioral features from smartphone, Fitbit, and Empatica’s supported data streams
- Add your own behavioral features (we can include them in RAPIDS if you want to share them with the community)
- Add support for new data streams if yours cannot be processed by RAPIDS yet
- Create visualizations for data quality control and feature inspection
- Extending RAPIDS to organize your analysis and publish a code repository along with your code
Hint
-
We recommend you follow the Minimal Example tutorial to get familiar with RAPIDS
-
In order to follow any of the previous tutorials, you will have to Install, Configure, and learn how to Execute RAPIDS.
-
Open a new discussion in Github if you have any questions and open an issue to report any bugs.
Frequently Asked Questions¶
General¶
What exactly is RAPIDS?
RAPIDS is a group of configuration files and R and Python scripts executed by Snakemake. You can get a copy of RAPIDS by cloning our Github repository.
RAPIDS is not a web application or server; all the processing is done in your laptop, server, or computer cluster.
How does RAPIDS work?
You will most of the time only have to modify configuration files in YAML format (config.yaml, credentials.yaml, and participant files pxx.yaml), and in CSV format (time zones and time segments).
RAPIDS pulls data from different data containers and processes it in steps. The input/output of each stage is saved as a CSV file for inspection; you can check the files created for each sensor on its documentation page.
All data is stored in data/, and all processing Python and R scripts are stored in src/.
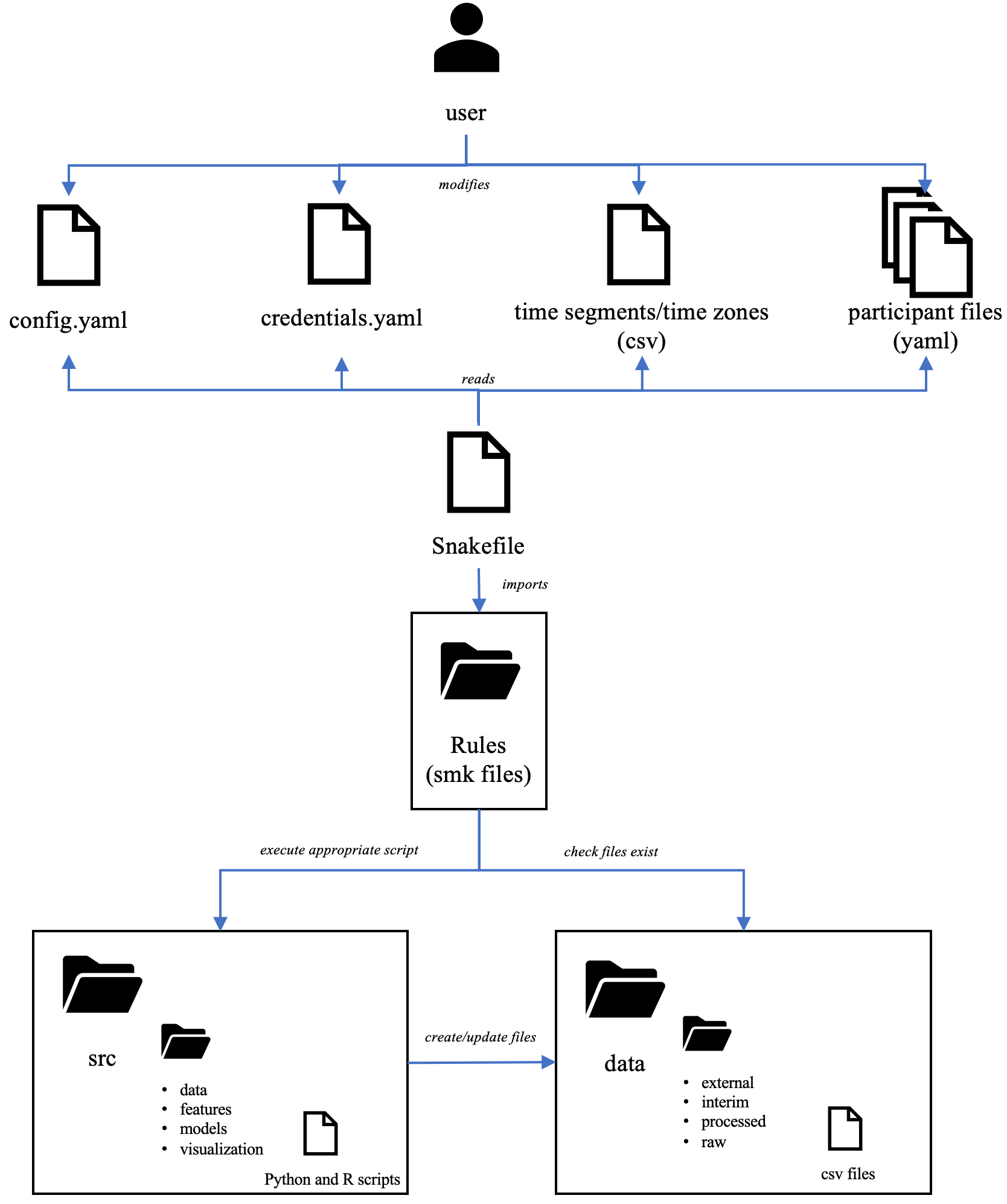
User and File interactions in RAPIDS
In the figure below, we represent the interactions between users and files. After a user modifies the configuration files mentioned above, the Snakefile file will search for and execute the Snakemake rules that contain the Python or R scripts necessary to generate or update the required output files (behavioral features, plots, etc.).
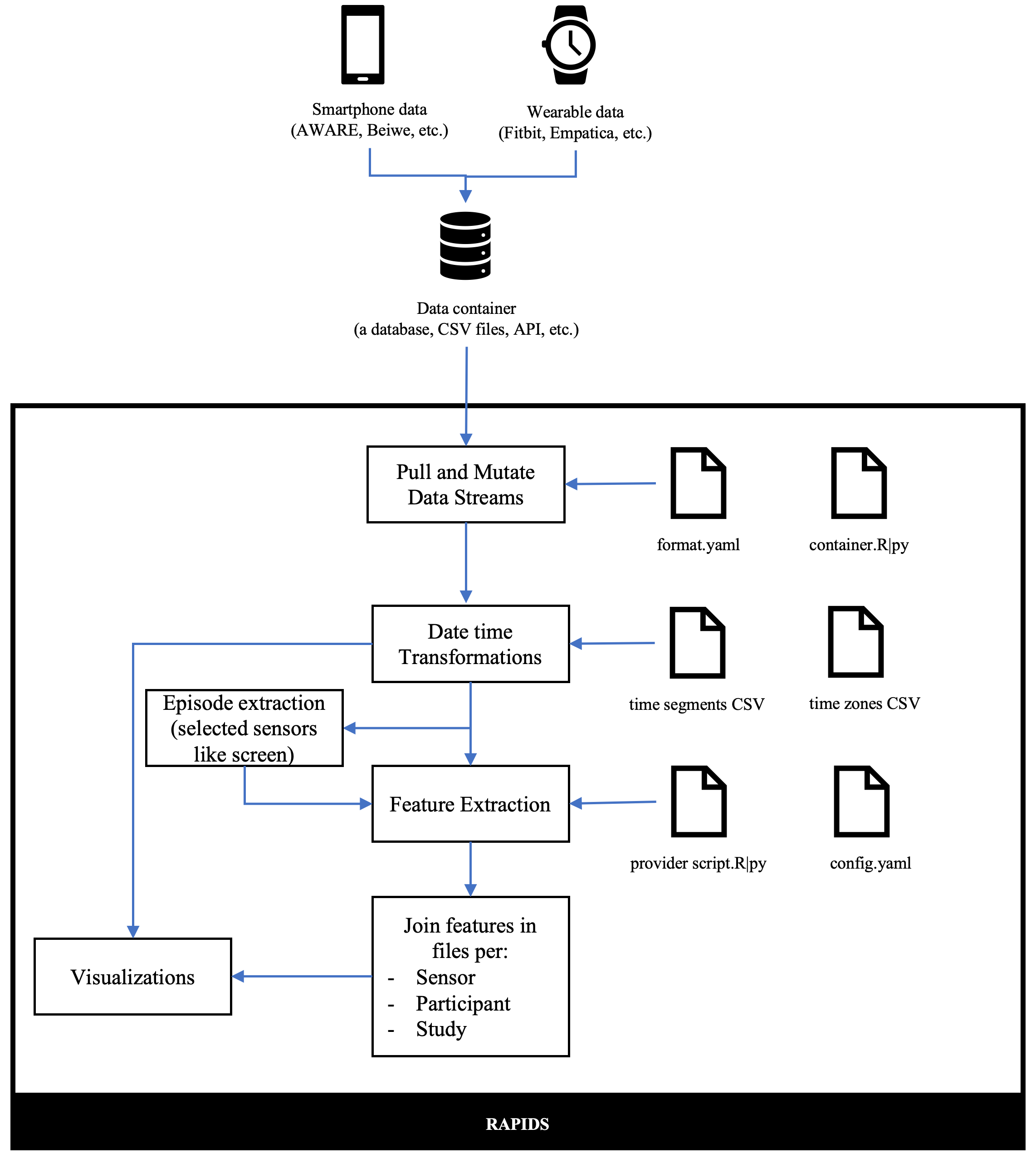
Data flow in RAPIDS
In the figure below, we represent the flow of data in RAPIDS. In broad terms, smartphone and wearable devices log data streams with a certain format to a data container (database, file, etc.).
RAPIDS can connect to these containers if it has a format.yaml and a container.[R|py] script used to pull the correct data and mutate it to comply with RAPIDS’ internal data representation. Once the data stream is in RAPIDS, it goes through some basic transformations (scripts), one that assigns a time segment and a time zone to each data row, and another one that creates “episodes” of data for some sensors that need it (like screen, battery, activity recognition, and sleep intraday data).
After this, RAPIDS executes the requested PROVIDER script that computes behavioral features per time segment instance. After every feature is computed, they are joined per sensor, per participant, and study. Visualizations are built based on raw data or based on calculated features.
Is my data private?
Absolutely, you are processing your data with your own copy of RAPIDS in your laptop, server, or computer cluster, so neither we nor anyone else can access your datasets.
Do I need to have coding skills to use RAPIDS?
If you want to extract the behavioral features or visualizations that RAPIDS offers out of the box, the answer is no. However, you need to be comfortable running commands in your terminal and familiar with editing YAML files and CSV files.
If you want to add support for new data streams or behavioral features, you need to be familiar with R or Python.
Is RAPIDS open-source or free?
Yes, RAPIDS is both open-source and free.
How do I cite RAPIDS?
Please refer to our Citation guide; depending on what parts of RAPIDS you used, we also ask you to cite the work of other authors that shared their work.
I have a lot of data, can RAPIDS handle it/ is RAPIDS fast enough?
Yes, we use Snakemake under the hood, so you can automatically distribute RAPIDS execution over multiple cores or clusters. RAPIDS processes data per sensor and participant, so it can take advantage of this parallel processing.
What are the advantages of using RAPIDS over implementing my own analysis code?
We believe RAPIDS can benefit your analysis in several ways:
- RAPIDS has more than 250 behavioral features available, many of them tested and used by other researchers.
- RAPIDS can extract features in dynamic time segments (for example, every x minutes, x hours, x days, x weeks, x months, etc.). This is handy because you don’t have to deal with time zones, daylight saving changes, or date arithmetic.
- Your analysis is less prone to errors. Every participant sensor dataset is analyzed in the same way and isolated from each other.
- If you have lots of data, out-of-the-box parallel execution will speed up your analysis, and if your computer crashes, RAPIDS will start from where it left off.
- You can publish your analysis code along with your papers and be sure it will run exactly as it does on your computer.
- You can still add your own behavioral features and data streams if you need to, and the community will be able to reuse your work.
Data Streams¶
Can I process smartphone data collected with Beiwe, PurpleRobot, or app X?
Yes, but you need to add a new data stream to RAPIDS (a new format.yaml and container script in R or Python). Follow this tutorial. Open a new discussion in Github if you have any questions.
If you do so, let us know so we can integrate your work into RAPIDS.
Can I process data from Oura Rings, Actigraphs, or wearable X?
The only wearables we support at the moment are Empatica and Fitbit. However, get in touch if you need to process data from a different wearable. We have limited resources, so we add support for additional devices on an as-needed basis, but we would be happy to collaborate. Open a new discussion in Github if you have any questions.
Can I process smartphone or wearable data stored in PostgreSQL, Oracle, SQLite, CSV files, or data container X?
Yes, but you need to add a new data stream to RAPIDS (a new format.yaml and container script in R or Python). Follow this tutorial. If you are processing data streams we already support like AWARE, Fitbit, or Empatica and are just connecting to a different container, you can reuse their format.yaml and only implement a new container script. Open a new discussion in Github if you have any questions.
If you do so, let us know so we can integrate your work into RAPIDS.
I have participants that live in different time zones and some that travel; can RAPIDS handle this?
Yes, RAPIDS can handle single or multiple timezones per participant. You can use time zone data collected by smartphones or collected by hand.
Some of my participants used more than one device during my study; can RAPIDS handle this?
Yes, you can link more than one smartphone or wearable device to a single participant. RAPIDS will merge them and sort them automatically.
Some of my participants switched from Android to iOS or vice-versa during my study; can RAPIDS handle this?
Yes, data from multiple smartphones can be linked to a single participant. All iOS data is converted to Android data before merging it.
Extending RAPIDS¶
Can I add my own behavioral features/digital biomarkers?
Yes, you can implement your own features in R or Python following this tutorial
Can I extract behavioral features based on two or more sensors?
Yes, we do this for PHONE_DATA_YIELD (combines all phone sensors), PHONE_LOCATIONS (combines location and data yield data), PHONE_APPLICATIONS_BACKGROUND (combines screen and app usage data), and FITBIT_INTRADAY_STEPS (combines Fitbit and sleep and step data).
However, we haven’t come up with a user-friendly way to configure this, and currently, we join sensors on a case-by-case basis. This is mainly because not enough users have needed this functionality so far. Get in touch, and we can set it up together; the more use cases we are aware of, the easier it will be to integrate this into RAPIDS.
I know how to program in Python or R but not both. Can I still use or extend RAPIDS?
Yes, you don’t need to write any code to use RAPIDS out of the box. If you need to add support for new data streams or behavioral features you can use scripts in either language.
I have scripts that clean raw data from X sensor, can I use them with RAPIDS?
Yes, you can add them as a [MUTATION][SCRIPT] in the format.yaml of the data stream you are using. You will add a main function that will receive a data frame with the raw data for that sensor that, in turn, will be used to compute behavioral features.